Launch
Free trial is live
Start with a 14-day trial, skip setup friction, and move into team billing when you're ready.
19 May 2026new
The scraping work nobody wants to do: scheduling, retries, schema checks, diffs, alerts. All built in. You get the data.
Beta open · 240+ engineers on the waitlist · Free plan available
Why we built this
Scraping isn't a script you write once.
It's infrastructure you maintain forever.
Sites change. Providers fail. Schemas drift. Cron jobs die silently at 3am and nobody finds out until the dashboard is empty for a week.
We turn that ongoing pain into a managed surface, so your team ships features, not babysits scrapers.
LLM extraction
<article class="product"> <h1>Air Max 90 - White</h1> <span class="price">$129.99</span> <div class="stock in">In stock</div> <div class="rating" data-score="4.7"> <span>4.7</span> (1,284 reviews) </div> <img src="/img/airmax90.jpg" /></article>{ "title": "Air Max 90 - White", "price": 129.99, "currency": "USD", "inStock": true, "rating": 4.7, "reviewCount": 1284, "image": "https://shop.example/img/airmax90.jpg"}How It Works
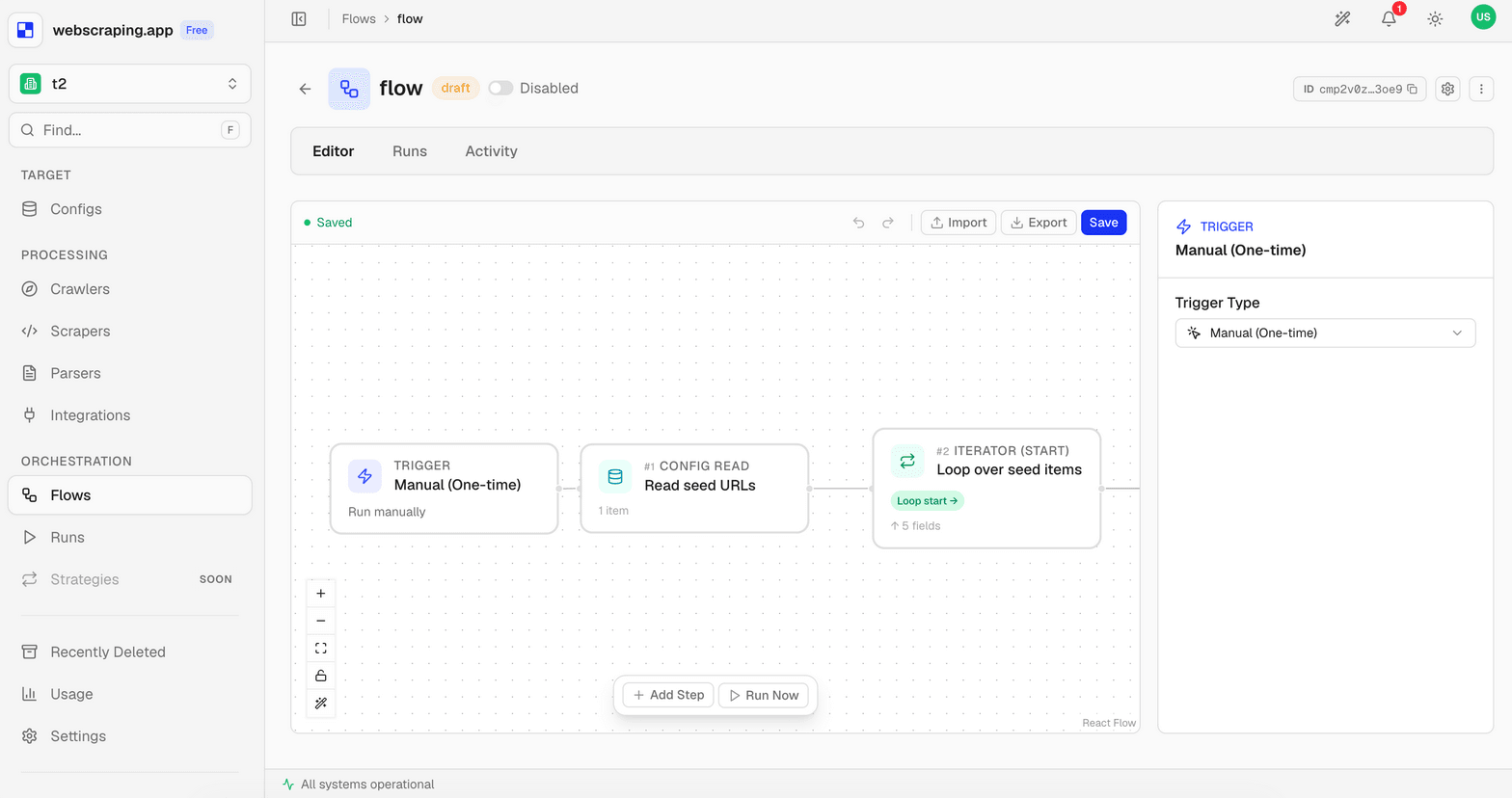
Connect sources, choose providers, and define inputs and outputs.
We handle routing, retries, and failures across providers.
Watch each run live - inspect every step and its output in real time.
Features
Your Data Layer
Crawler finds 142 URLs
Writes them to the shared config as input items
Scraper processes each URL
Processes each item using your configured providers
Results are saved as structured outputs
Use them, export them, or pass them to the next step
Launch
Start with a 14-day trial, skip setup friction, and move into team billing when you're ready.
19 May 2026new
Automation
Pause runs, resume failed workflows, set smarter timeouts, and recover without starting from scratch.
18 May 2026
Free plan - 500 runs to try it out. First scrape in under 60 seconds.